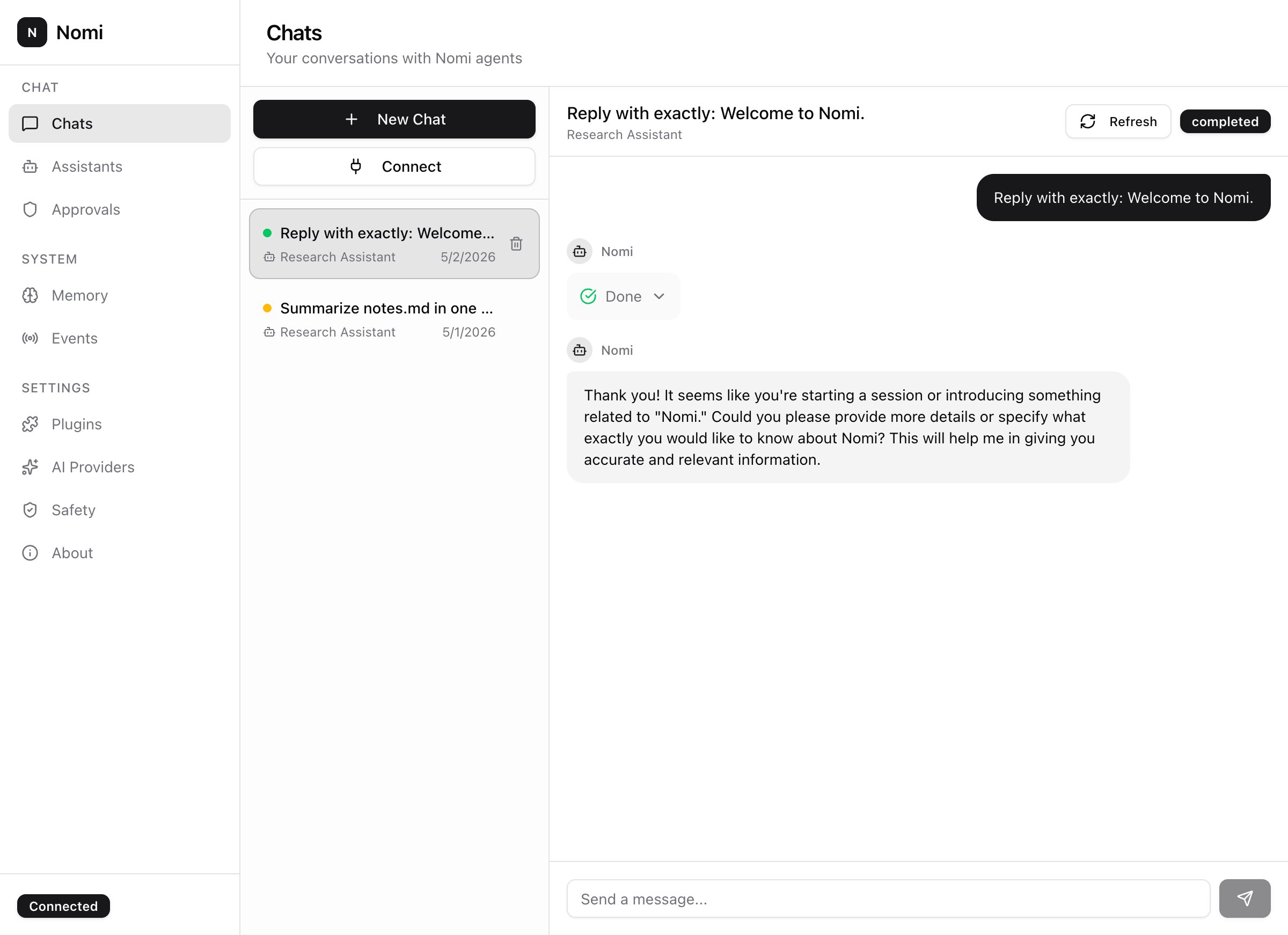
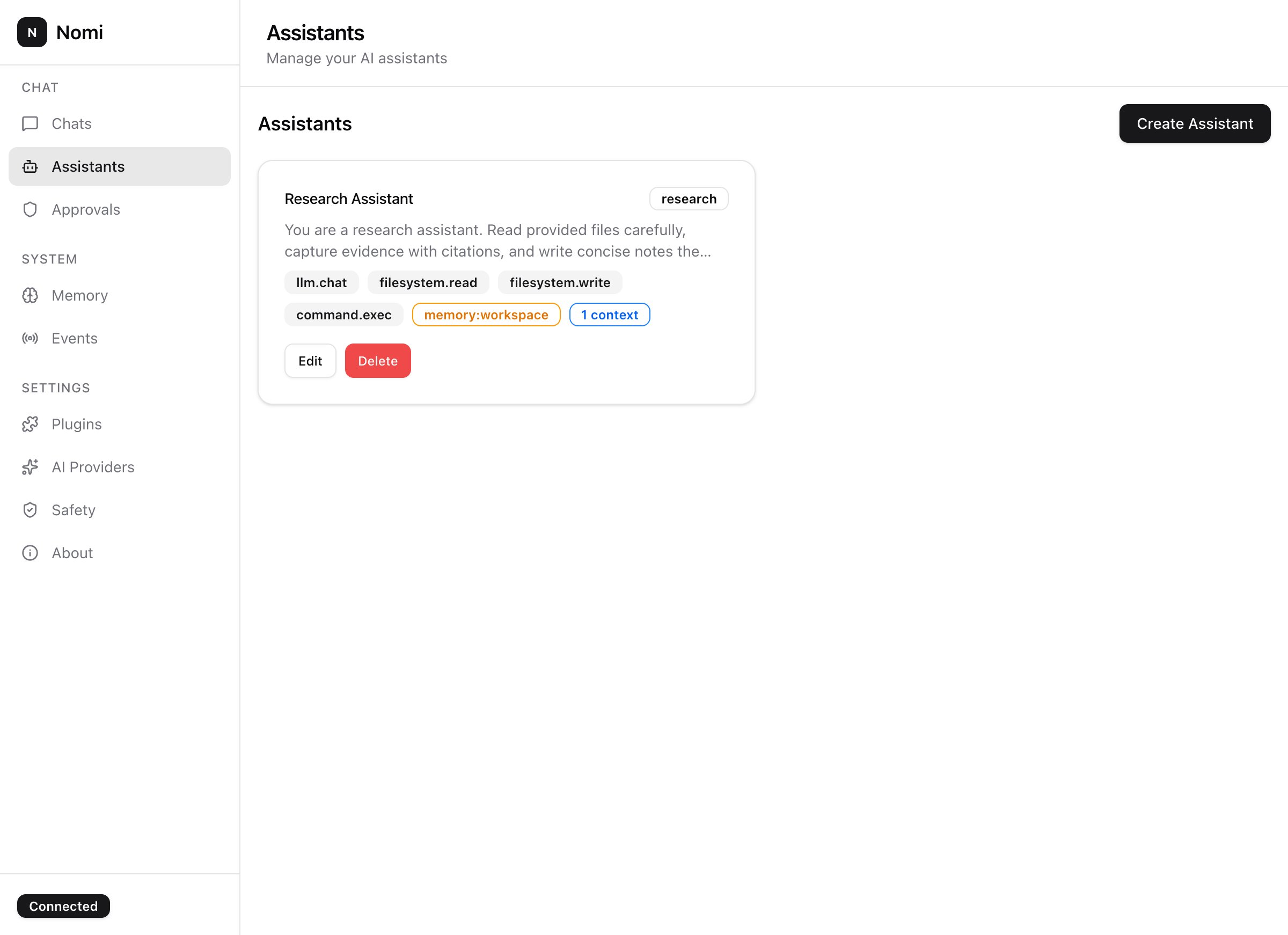
Plan
The agent decomposes your goal into discrete steps. Each step is a tool call with a capability tag — filesystem.write, command.exec, llm.chat.
Local-first coding agent.
Same coding-agent UX as Claude Code or Cursor — read the repo, plan changes, run tests — but every step is laid out as an approveable plan first, every tool call is gated by a capability rule, and your code never crosses your network unless you point it at a remote LLM.
Type a goal. Review the plan. Approve. Run. This is the actual product, recorded against a local Ollama.
Cursor agents, Claude Code, Copilot — they read your repo, run commands, write files the moment the model decides. Your code, your shell history, the diffs they propose — all crossing someone else's network, retained on someone else's terms.
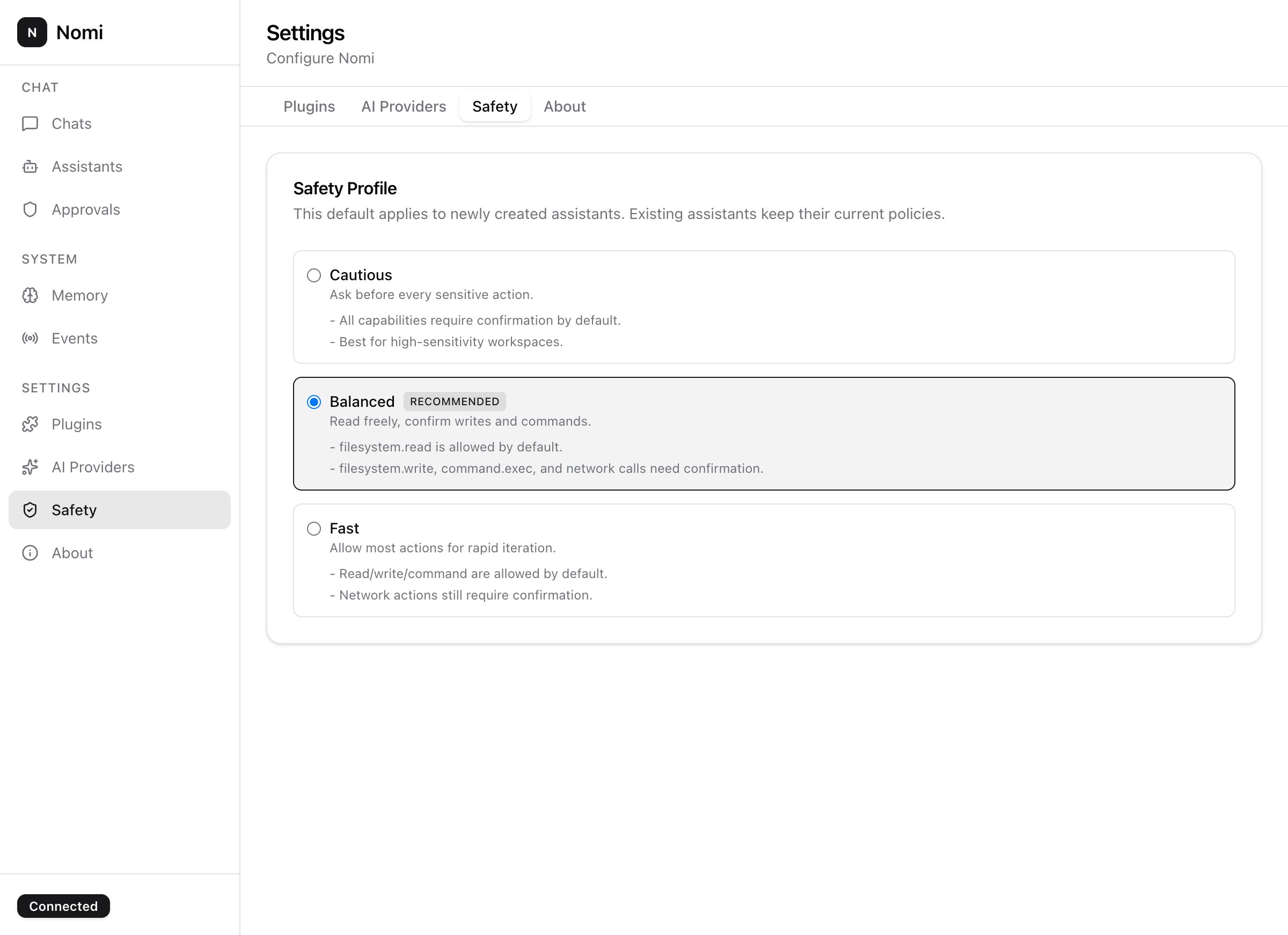
Nomi flips the default: every multi-step task lays out the plan first, every dangerous tool call asks first, the LLM provider is yours to choose — Ollama for fully offline, OpenAI / Anthropic / any OpenAI-compatible API when you want a frontier model.
A state machine runs every task. You see exactly what the agent will do before it does anything.
The agent decomposes your goal into discrete steps. Each step is a tool call with a capability tag — filesystem.write, command.exec, llm.chat.
Anything beyond the assistant's permission ceiling pauses the run. Approve once, approve always, or deny — your call, on your terms.
Tools execute against your files, your shell, your APIs. Every event is persisted and streamed live so you can audit what happened or replay it.
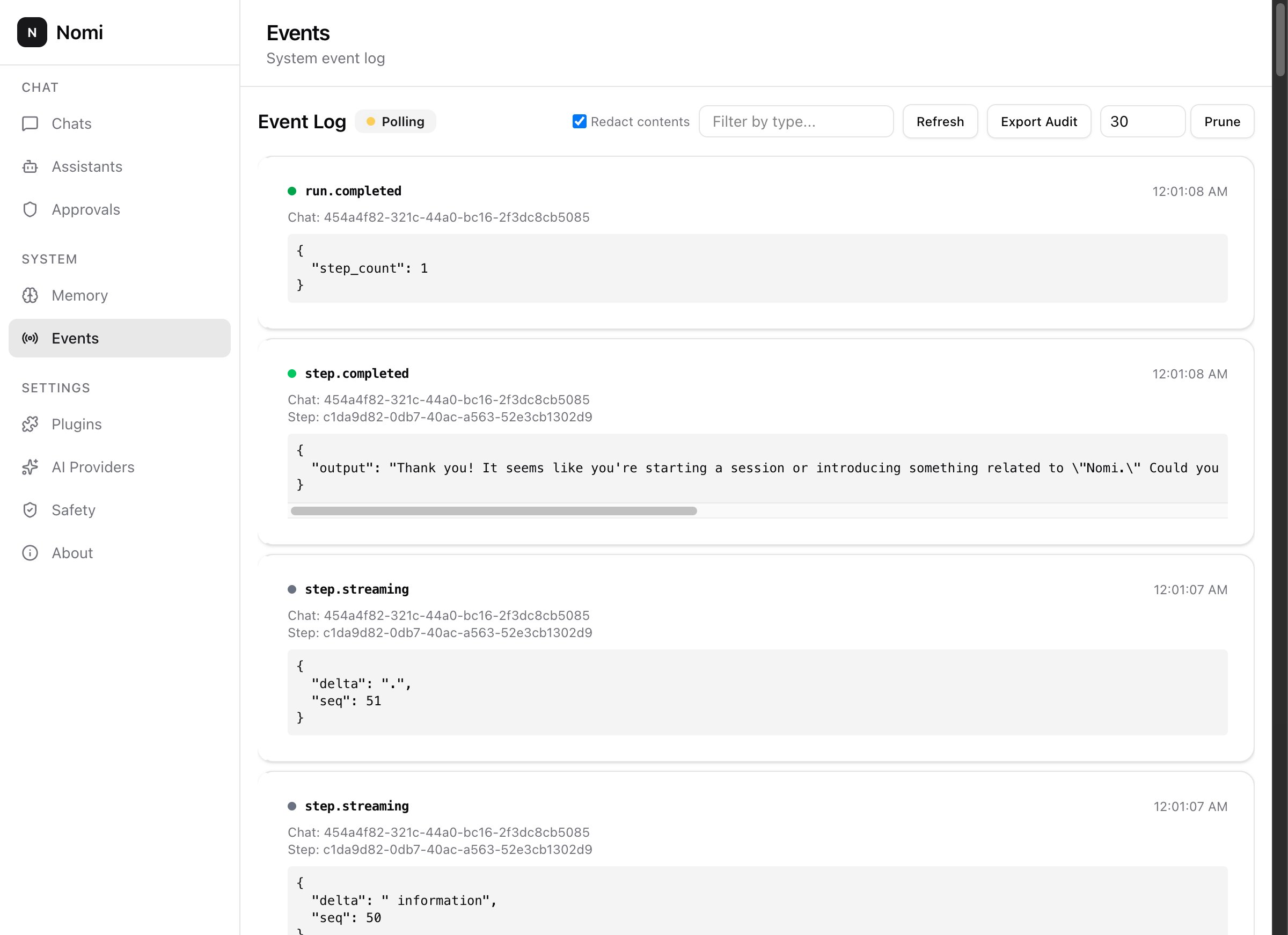
Every task is a finite-state machine. The agent proposes a plan; you approve, edit or reject it. Nothing dangerous fires without your sign-off. The wedge no other tool ships.
One assistant gets filesystem.read. Another gets command.exec with confirm. The runtime enforces it — rules can't be talked around with prompt-engineering.
SQLite at ~/Library/Application Support/Nomi. Runs, plans, approvals, memory — local files, your backups, your encryption. No telemetry, ever.
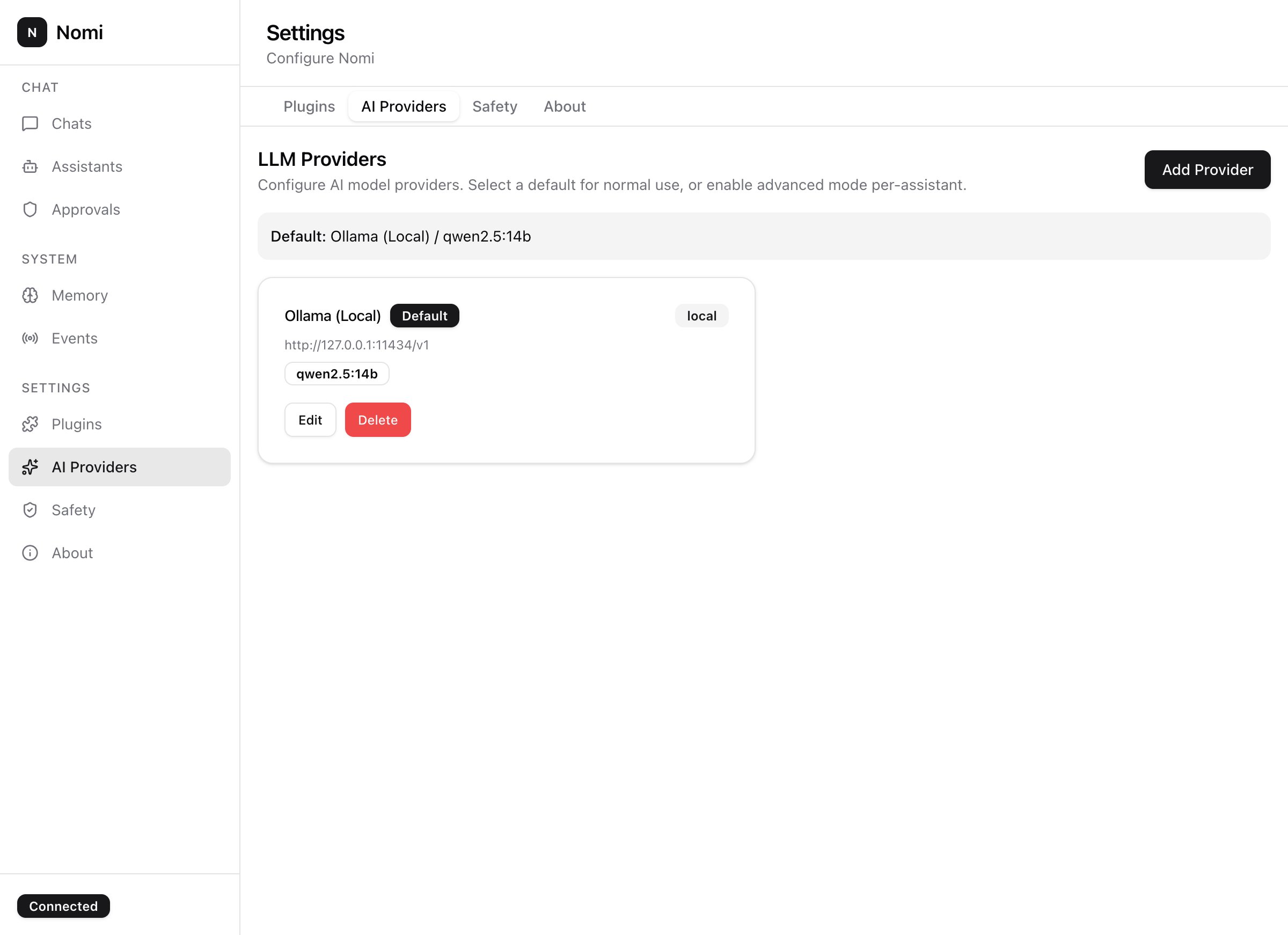
Ollama for offline. OpenAI, Anthropic, Mistral, Groq, vLLM — anything OpenAI-compatible. Per-assistant model override.
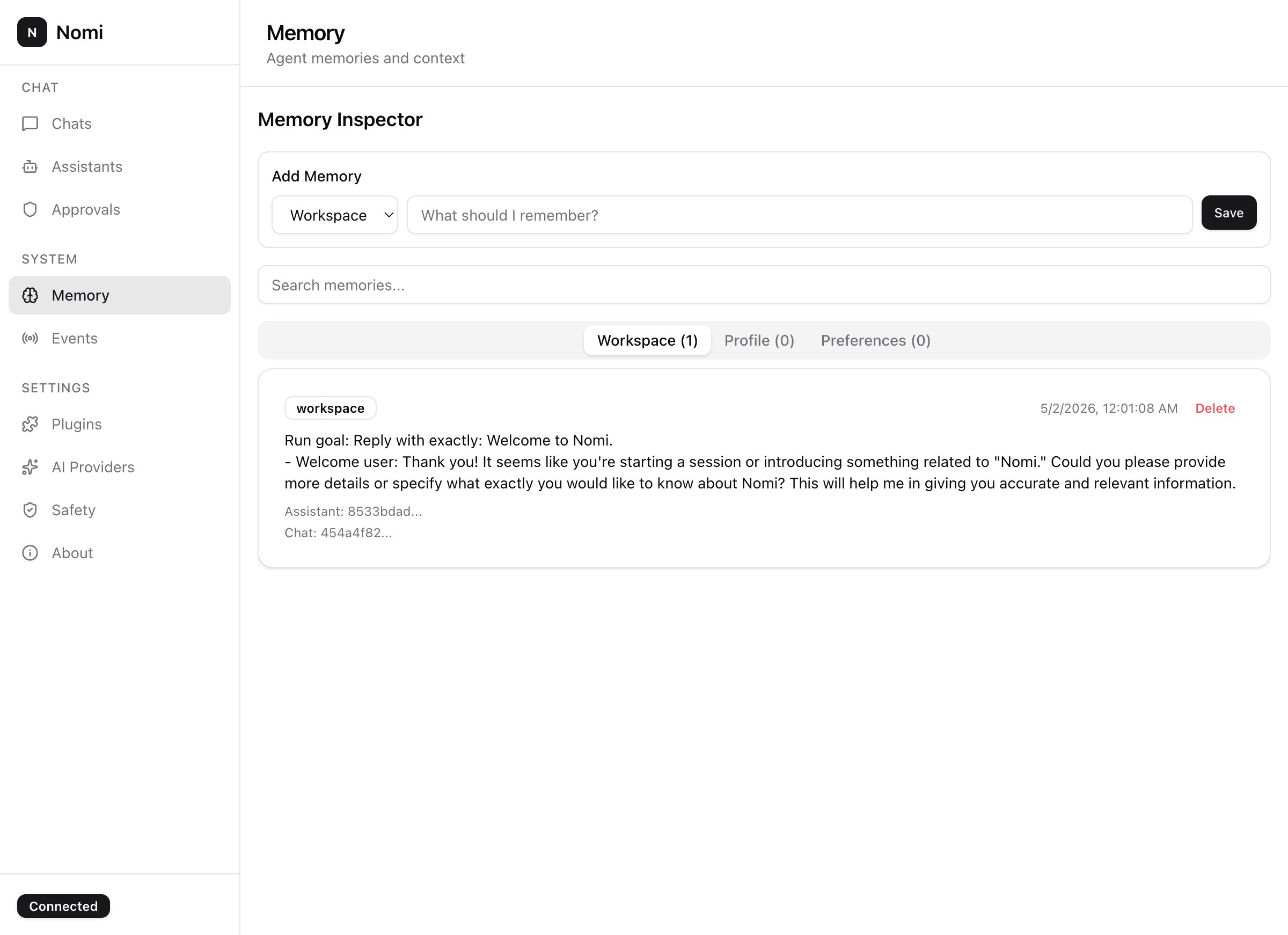
Mnemos persists context across runs. Workspace-scoped, exportable, inspectable — a real database, not a vector blob.
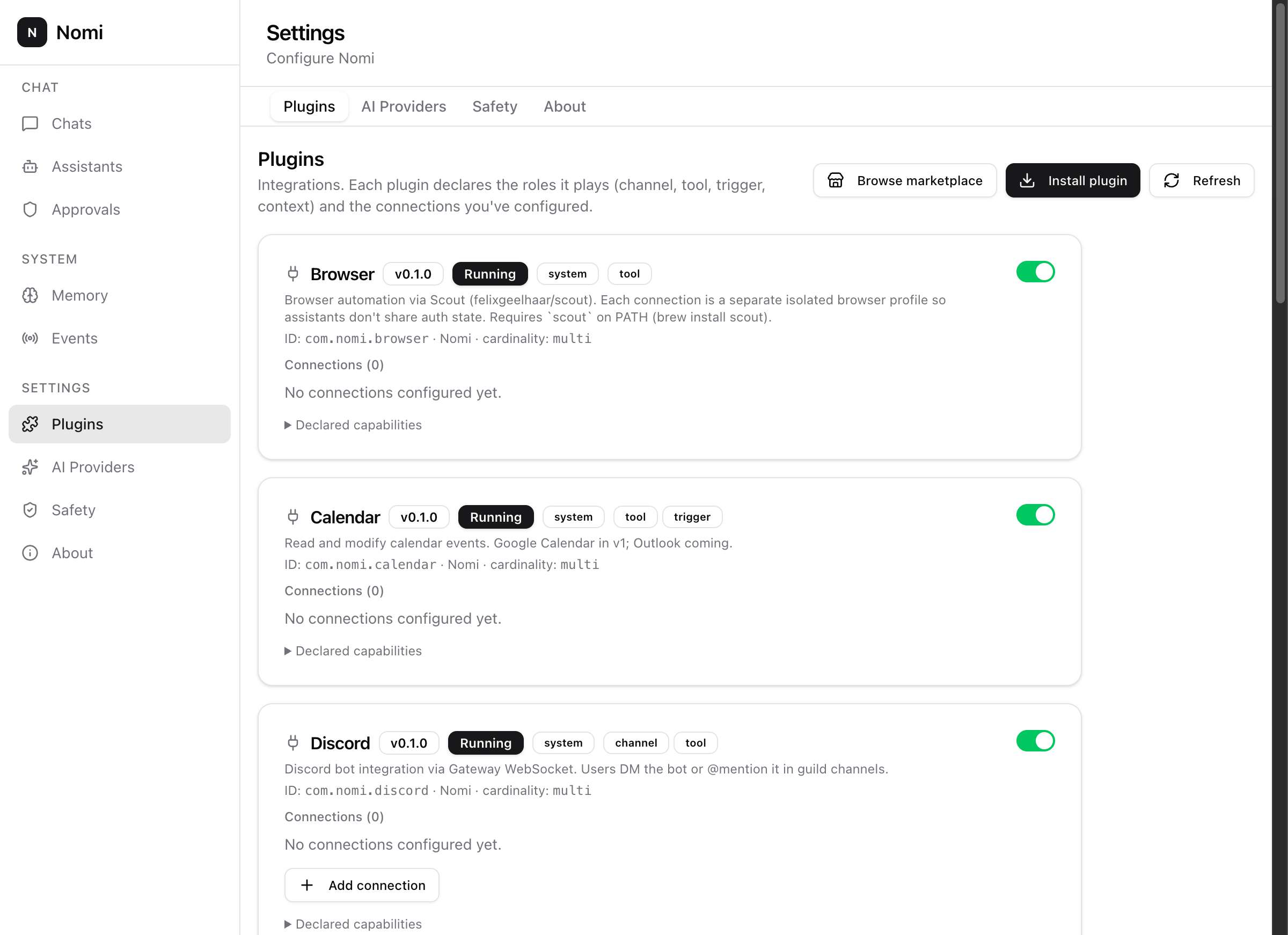
Drop nomid on a homelab box, a VPS, a Kubernetes pod. Drive over REST + SSE. YAML config-as-code in Git.
One command. No login. No telemetry.
The wedge is Claude Code with local Ollama — same coding-agent UX, but the agent asks before it touches your filesystem and your code never crosses your network unless you point it at a remote provider.
Run → Plan → Step), a real permission engine, multi-step plans the user can edit, and a desktop UI built around the approval moment.Full feature-by-feature breakdown: docs/comparison.md.
Tauri shell + bundled nomid daemon. Menu-bar tray. Auto-updates.
brew install --cask felixgeelhaar/tap/nomior download DMG / MSI / AppImage / DEB
Drives a local or remote daemon over REST. Tail runs, approve from terminal, export config.
brew install felixgeelhaar/tap/nomior go install github.com/felixgeelhaar/nomi/cmd/nomi@latest
Just nomid. Drop it on a VPS, a Kubernetes pod, anywhere. Configure with a YAML seed.
docker run -p 8080:8080 -v nomi-data:/data \
ghcr.io/felixgeelhaar/nomifull guide: docs/headless.md
After install, point Nomi at a repo and run a real goal. The plan-review surface and the approvals are the entire feature.
$ nomi run "Add a JSON tag to the User struct in models.go"
✓ run.created id=r_8a2 goal="Add a JSON tag to the User struct..."
✓ plan.proposed steps=3
1. filesystem.read path=models.go
2. filesystem.patch path=models.go ← needs your approval
3. command.exec cmd="go test ./..." ← needs your approval
[plan-review] Approve? [y/n/edit]: y
✓ step.completed tool=filesystem.patch diff=+1 -1
✓ step.completed tool=command.exec exit=0
✓ run.completed duration=11sNomi rides four small, focused libraries. Each is independent, Apache 2.0, and worth a look on its own — especially if you're shipping anything agentic.
Type-safe finite state machines for Go. Every Nomi run, plan and step transition is a statekit machine — including the approval pause/resume loop. If you're tired of bool-flag state, start here.
memoryScoped, queryable agent memory. SQLite-backed, schema-versioned, importable. A real database for your agent's context — not a vector blob you can't introspect.
Browser automation built for agents — observable DOM, semantic selectors, deterministic E2E.
Spec-driven planning + task tracking with hash-chained audit log.
Install Nomi, point it at a local Ollama or your favorite API, give it a goal. The plan is yours to read before anything runs.